MLOps artifacts: data, model, and code
- Edwin Kuss
- 15 min
What they are and why they matter in modern MLOps
In modern machine learning workflows, everything revolves around three core artifacts: data, models, and code. These aren’t abstract concepts — they are the essential building blocks that determine whether ML systems are reliable, reproducible, and scalable.
Most MLOps frameworks consider these artifacts the foundation of the entire lifecycle. To keep ML systems stable and repeatable, teams must maintain pipelines that are cleanly versioned, automated, and traceable, enabling them to:
- train new model versions on consistent, high-quality datasets
- validate and compare experiments across iterations
- deploy models without disrupting production systems
- reproduce results months later using the same inputs and configurations
- track lineage across data, code, and model artifacts
Ultimately, the purpose of MLOps is to ensure that data, model artifacts, and code evolve in sync — in a way that is controlled, auditable, and repeatable.
In this article, we break down each of the three artifact types and explore how they shape a reliable ML workflow. You’ll learn how they interact, why synchronized evolution matters, and which best practices help teams build stable, production-ready ML systems.
Data: the first and most critical MLOps artifact

Data forms the foundation of every machine learning workflow. It is not just a raw input — it is a living, evolving artifact that directly determines how well models perform, how reliably they behave in production, and whether results can be reproduced months or years later. Modern ML systems rely on diverse data types — streaming feeds, batch datasets, object storage, labeled samples, and both online and offline feature stores — all of which are represented in the MLOps lifecycle.
Because this data arrives from many systems and is processed in different ways, managing it becomes one of the most complex and essential responsibilities in MLOps.
Why data matters
High-quality, well-managed data enables ML teams to:
- Train models that accurately reflect real-world behavior
- Detect drift as environments change
- Reproduce past results using the same dataset versions
- Maintain compliance with regulatory and privacy rules
- Reduce technical debt and pipeline instability
In practice, model performance depends more on the data than on the algorithm itself — making data management a central pillar of every ML system.
Key responsibilities in data management
To ensure that data remains a dependable artifact, teams must:
1. Ingest and integrate data from various operational systems (databases, streams, cloud storage, APIs, feature stores).
2. Preprocess and engineer features by cleaning, transforming, and enriching data into training-ready formats.
3. Validate data quality and integrity, catching anomalies, schema drift, null values, outliers, and inconsistencies early.
4. Track data versions and lineage to know exactly which dataset produced which model.
5. Enforce governance and access control to comply with organizational policies and external regulations.
These responsibilities map directly to core elements of the MLOps workflow — including feature engineering pipelines, validation steps, data engineering processes, and the feedback loop from production to training.
Modern MLOps platforms increasingly support this through artifact tracking, which maintains structured metadata for datasets, versions, and lineage.
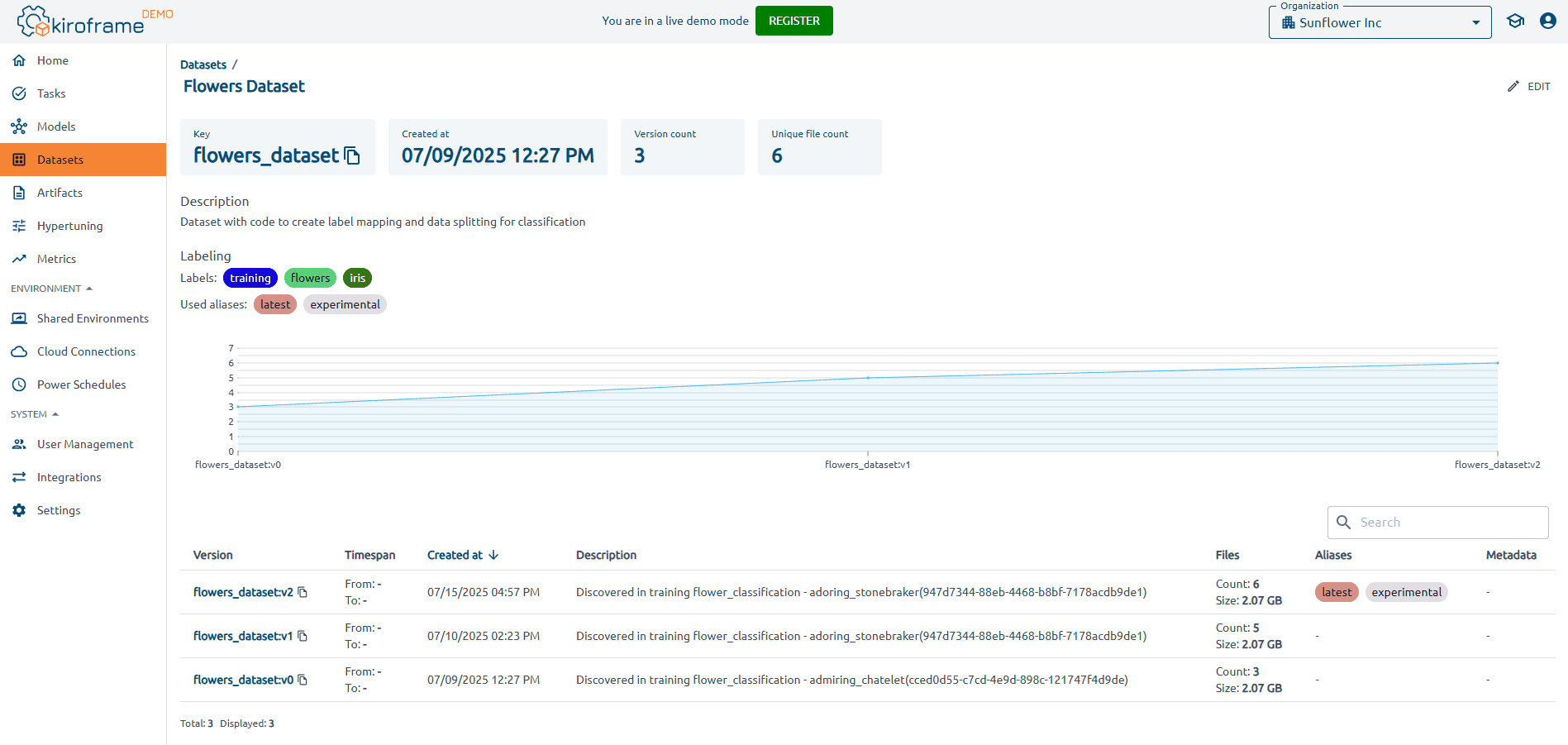
Kiroframe contributes here by storing dataset lineage and version information alongside model and code artifacts, helping teams maintain consistency across training iterations and understand how data evolves.
Common data-related mistakes
Many ML initiatives fail due to recurring issues such as:
- Using inconsistent dataset snapshots across training and serving
- Manually creating datasets, leading to drift and human errors
- Lack of feature versioning or lineage tracking
- Poor visibility into how data changes over time
- Missing or incomplete validation before model training
- No monitoring for data drift in production
These mistakes break reproducibility and cause silent model degradation.
How data fits into the MLOps workflow
Data influences every phase of the ML lifecycle:
- Project initiation → determine what data is needed
- Feature engineering zone → generate features for training and serving
- Data engineering zone → validate, transform, and pipeline datasets
- Experimentation → feed versioned data into training pipelines
Model serving → compare production inputs with training distributions
Data continuously flows between these steps, creating a feedback loop that keeps models relevant and high-performing.
Best practices for managing data in MLOps
Modern teams follow these principles:
- Automate dataset creation using orchestrated pipelines
- Validate data at every step, not just before training
- Version datasets, features, and preprocessing logic
- Use both online and offline feature stores for consistency
- Document datasets through catalogs and metadata systems
- Monitor drift continuously to detect when retraining is needed
- Apply governance to enforce privacy, access, and retention policies
These practices ensure that data remains consistent, traceable, and reliable — enabling reproducible experiments and stable production systems.
Model: the core artifact driving ML predictions
While data is the foundation, models are the operational heart of any ML system. They transform input signals into predictions and decisions used by real applications. In MLOps, a model is not just a trained file — it is a versioned, governed, and lifecycle-managed artifact with strict requirements for reproducibility, traceability, and monitoring.
Modern workflows distinguish several model-related components (all visible in the diagram).
Model-related artifacts
ML model (raw experimental output)
This is the model produced during training — often one of many variations generated during experimentation. It is not yet validated for production use but represents a candidate version to evaluate and compare.
Prod-ready ML model (validated and approved)
A prod-ready model passes quality, performance, and safety checks and is approved for deployment. It is fully reproducible, documented, and stable enough to serve real user traffic.
Model registry (central catalog of all versions)
The registry stores every model version along with its metadata, lineage, and performance metrics. It serves as the authoritative source for selecting, promoting, and rolling back models in production.
ML metadata store (hyperparameters, metrics, lineage)
A metadata store records the training context, including hyperparameters, dataset versions, code commits, environment details, and evaluation metrics. It ensures all experiments are traceable and reproducible.
Model serving component (online inference)
This component hosts the model in a production environment and handles real-time prediction requests. It ensures low-latency, scalable, and reliable inference for downstream applications.
Model monitoring component (live performance & drift)
The monitoring system tracks how the model behaves in production — including accuracy, input/output distributions, latency, and drift. It detects when models degrade and signals when retraining is needed.
Together, they form the backbone of the model’s lifecycle — from experimentation to production.
Why models matter
Models directly influence:
- prediction accuracy
A model ultimately determines how well the system understands the data’s patterns and how reliable its predictions are. Even small improvements in model accuracy can meaningfully boost downstream decision quality and automation rates.
- user experience
Models directly shape how users interact with intelligent products — from personalized recommendations to fraud alerts to search quality. A better model means smoother interactions, fewer errors, and higher user trust.
- business KPIs
Model performance closely aligns with business metrics such as conversion rate, churn reduction, ticket automation, and anomaly detection efficiency. Well-optimized models often unlock measurable ROI gains across multiple business units.
- regulatory compliance
In regulated industries, models must meet transparency, fairness, bias, and auditability requirements. Poorly managed model artifacts can lead to compliance violations, legal exposure, or the inability to justify model decisions.
- production stability
A model is part of a larger production system, so instability — e.g., latency spikes, output anomalies, or drift — can cascade into outages and degraded service quality. Properly versioned, monitored, and validated models ensure consistent and predictable system behavior.
A slight change in model weights or training conditions can dramatically alter its behavior, which is why structured management is essential.
Modern MLOps treats models as versioned, reproducible software artifacts rather than ad-hoc files scattered across notebooks.
Key responsibilities in model management
To keep models reliable throughout their lifecycle, MLOps teams must ensure:
- Experimentation & parameter search
Selecting optimal hyperparameters, architectures, and training setups requires:
- automated experiment scheduling
- parallel training runs
- hardware utilization control (CPU/GPU)
- tracking results, metrics, and configurations
This transforms experimentation from guesswork into a structured scientific process.
- Model registration & metadata tracking
Every meaningful experiment should produce:
- a versioned model artifact
- its metrics
- training dataset version
- hyperparameters
- code commit
- environment information
A Model Registry becomes the single source of truth for all model versions.
Kiroframe supports this workflow by storing model versions together with their experiment metadata, performance metrics, and training configurations — ensuring full lineage and reproducibility without being tied to a specific training framework.
- Deployment into production
Moving a model from experimentation to real users requires:
- approval workflows
- packaging (e.g., Docker, ONNX, TensorRT)
- CI/CD pipelines
- canary or shadow deployment
- version rollback procedures
Consistent deployment prevents breaking downstream services.
- Monitoring model behavior
After deployment, monitoring must confirm:
- prediction quality (accuracy, precision, RMSE, etc.)
- data drift & concept drift
- latency & throughput
- resource usage
- anomalies in input/output distribution
This feedback loop determines when retraining is necessary.
- Automated retraining pipelines
When drift or degradation is detected, the system can:
- launch retraining
- evaluate new versions
- compare metrics
- push a new production version if it performs better
Typical challenges in managing ML models
Teams often face failures because of:
- untracked experiments
- no lineage (cannot reproduce the model)
- inconsistent train/serve environments
- manual model promotion without governance
- missing monitoring, causing silent degradation
- storing model files locally or scattered across systems
All of these undermine reproducibility and trust in production.
Integrating models into the MLOps workflow
In the large diagram, models interact with every zone:
- Data Engineering Zone → provides validated, versioned inputs
- Experimentation Zone → generates trained models + metrics
- Model Registry & Metadata Store → maintain lineage and approval workflow
- Serving Zone → deploys models for real calls
- Monitoring Zone → feeds real-world insights back to experimentation
This creates a continuous loop:
Data → Training → Evaluation → Deployment → Monitoring → Retraining
Best practices for managing models in MLOps
Leading ML teams follow these guidelines:
- Use a dedicated Model Registry for version control
- Track metrics, hyperparameters, datasets, and code commits for every experiment
- Standardize model packaging and deployment methods
- Automate evaluation and promotion workflows
- Implement continuous monitoring and drift detection
- Maintain train/serve consistency through containers or environment locking
- Store full lineage so every production model is explainable and reproducible
With these practices, models remain reliable, auditable, and easy to improve over time.
Code: the automation engine of MLOps
In any MLOps system, code is the glue that holds everything together. While data and models define what the system learns, code defines how it learns, scales, and operates. It automates the entire lifecycle — from data ingestion to training, validation, deployment, and serving.
In the MLOps conceptual framework (the attached diagram), code appears in almost every layer.
What code powers in an MLOps system
- Data transformation rules
These scripts clean, validate, normalize, and reshape raw data so it’s ready for downstream pipelines. They ensure that both training and serving receive consistent, high-quality input.
- Feature engineering rules
Feature logic defines how raw inputs are converted into meaningful features. Versioned feature code guarantees that training and inference use identical transformations, preventing train–serve skew.
- Data pipeline code
ETL/ELT pipelines move, join, enrich, and prepare data at scale. This code keeps data flows reliable, automated, and lineage-aware across batch, streaming, and hybrid environments.
- Model training code
Training code includes algorithms, hyperparameters, optimization routines, and evaluation steps. It defines exactly how models are produced, making experiments reproducible and comparable.
- ML workflow code (orchestration)
Workflow code coordinates complex sequences such as data prep → training → evaluation → registration → deployment. Orchestrators (Airflow, Dagster, Kubeflow Pipelines) automate these multi-step processes.
- Model serving code
Serving code packages the trained model into an application—often an API or microservice—that responds to real-time or batch prediction requests. It ensures fast, stable inference in production.
- Monitoring code
Monitoring scripts track data drift, model decay, performance slowdowns, and resource usage. They may also trigger automated retraining or alert teams when issues appear.
On top of this, modern teams often maintain Infrastructure as Code (IaC) — such as Terraform, Pulumi, and CloudFormation — to provision compute, storage, orchestration engines, and CI/CD components reproducibly.
How code powers automation in Machine Learning systems
Repeatability and consistency
Code ensures that every pipeline step — from data preparation to model serving — can be executed identically across environments (dev, staging, production). This eliminates “it worked on my machine” issues and reduces drift between training and serving logic.
Scalability and performance
Codified workflows enable systems to scale horizontally using frameworks such as Kubernetes, Ray, Spark, or distributed training libraries. Without automated code, scaling ML is impossible.
Automation of the ML lifecycle
Code orchestrates complex loops:
Data → Features → Training → Evaluation → Model registry → Deployment → Monitoring → Retraining
Each step is implemented, validated, triggered, and logged as code — enabling fully automated ML systems.
- Lineage and auditability
Because all logic lives in version control, teams can trace exactly:
- which code version trained which model,
- which data pipeline produced which dataset,
- which introduced changes in performance.
This is crucial for governance, debugging, and regulatory compliance.
The code layer: automating data, training, and serving
Within the attached framework:
- Data Engineering Zone (B1 + B2) relies on pipeline code and feature logic to produce stable training sets.
- ML Experimentation Zone (C) runs training and evaluation code repeatedly to test configurations and hyperparameters.
- CI/CD Zone + Serving Components use deployment code to deploy models to production automatically.
- Monitoring Loops uses tracking and analytics code to detect drift and trigger retraining.
Code ties all zones together into one reproducible graph.
Best practices for managing code in MLOps
- Use Git-based version control for everything — pipeline code, training scripts, configs, infra manifests.
- Store configuration separately from code using YAML/TOML or environment managers.
- Apply CI/CD for ML to test pipeline components and automate deployments.
- Use containerization (Docker) and, ideally, standardized environments (conda, virtualenv, Nix).
- Implement IaC to provision compute and orchestrators reproducibly.
- Maintain a single source of truth for inference logic shared between training and serving.
- Introduce orchestration tools (e.g., Airflow, Dagster, Kubeflow Pipelines, Prefect) instead of ad hoc scripting.
- Document pipeline flows for transparency and maintainability.
MLOps artifact | What it is | Why it matters | Key responsibilities | Common mistakes | Best practices | How it fits into the workflow |
Data | Inputs used to train and evaluate ML models | Determines model performance, reliability, and fairness | Collection, cleaning, versioning, feature engineering, validation | Poor versioning, inconsistent preprocessing, data drift, low-quality labels | Automate pipelines, use DVC, track lineage, and validate distributions | Feeds pipelines, training, evaluation, and monitoring; drives retraining triggers |
Model | The algorithm + parameters learned from data | Produces predictions powering real applications | Experimentation, training, tuning, storing in registry, deployment | Untracked experiments, missing metadata, inconsistent artifacts, outdated models | Use experiment tracking, model registry, and reproducibility practices | Serves predictions, connects to CI/CD, monitored for drift, triggers retraining |
Code | Logic that processes data, trains models, and deploys systems | Automates ML lifecycle and reduces errors | Implementing pipelines, orchestration, serving, validation, IaC | Mixing pipeline logic with experiments, no version control, inconsistent environments | Git discipline, modular pipelines, IaC, containerization | Orchestrates all stages: data prep → training → serving → monitoring |
Where Kiroframe helps
Kiroframe strengthens the code-driven workflow by helping teams store, track, and compare ML and data artifacts generated by their training code and pipelines.
Its experiment tracking, dataset lineage, and profiling tools ensure that every code-generated output — from datasets to model weights — is fully traceable, making debugging and iteration far easier.
💡Like most IT processes, MLOps has maturity levels. They help companies understand where they are in the development process and what needs to be changed.
You might be also interested in our article ‘MLOps maturity levels: the most well-known models’ →