Key MLOps principles: Best practices for robust Machine Learning Operations
- Edwin Kuss
- 10 min

Table of contents
- MLOps Lifecycle: Key components for sustaining Machine Learning models
- MLOps principles
- 1. Versioning — the foundation of reliable MLOps
- 2. Testing — ensuring model quality and pipeline reliability
- 3. Automation — streamlining Machine Learning workflows
- 4. Monitoring and tracking
- 5. Reproducibility — building reliable and transparent ML workflows
MLOps Lifecycle: Key components for sustaining Machine Learning models
In our earlier posts, we described MLOps as a set of methods and procedures intended to effectively and methodically develop, construct, and implement machine learning models. Creating and sustaining a process over time is a critical MLOps stage. This process describes the actions required to develop, implement, and manage machine learning models. It involves understanding the business problem in a structured manner, performing data engineering for preparation and preprocessing, executing machine learning model engineering from design to evaluation, and managing code engineering to serve the model.
All components of the MLOps workflow are interconnected and operate cyclically, which means revisiting earlier steps may be necessary at any stage. This interdependence defines the MLOps lifecycle, essential for ensuring that the machine learning model remains effective and continues to address the business problem identified at the outset. Thus, maintaining the MLOps lifecycle by adhering to established MLOps principles is vital.
MLOps principles
MLOps principles encompass concepts aimed at sustaining the MLOps lifecycle while minimizing the time and cost of developing and deploying machine learning models, thereby avoiding technical debt. To effectively maintain the lifecycle, these principles must be applied across various workflow stages, including data management, machine learning models (ML models), and code management. Key principles include versioning, testing, automation, monitoring and tracking, and reproducibility. Successfully implementing these principles requires appropriate tools and adherence to best practices, such as proper project structuring.
In this article, we prioritize these principles based on their significance and the sequence in which they should be applied. However, it is important to note that all these principles are crucial for mature machine learning projects; they are interdependent and support one another.
1. Versioning — the foundation of reliable MLOps
Versioning is one of the most critical pillars of MLOps, ensuring that every component of a machine learning workflow — from data to models to code — is traceable, reproducible, and recoverable. Without proper version control, it becomes nearly impossible to identify which version of a dataset, model, or pipeline produced specific results — making collaboration, debugging, and scaling extremely difficult.
In MLOps, versioning applies to three main areas:
Data versioning
Data forms the backbone of any ML system. Managing different dataset versions — including features, metadata, and preprocessing pipelines — ensures full traceability across experiments. Tools like Git and DVC (Data Version Control) make it possible to track changes to large datasets, maintain lineage, and revert to earlier versions when necessary. Proper data versioning also supports compliance by documenting exactly how and when data was used for model training.
Model versioning
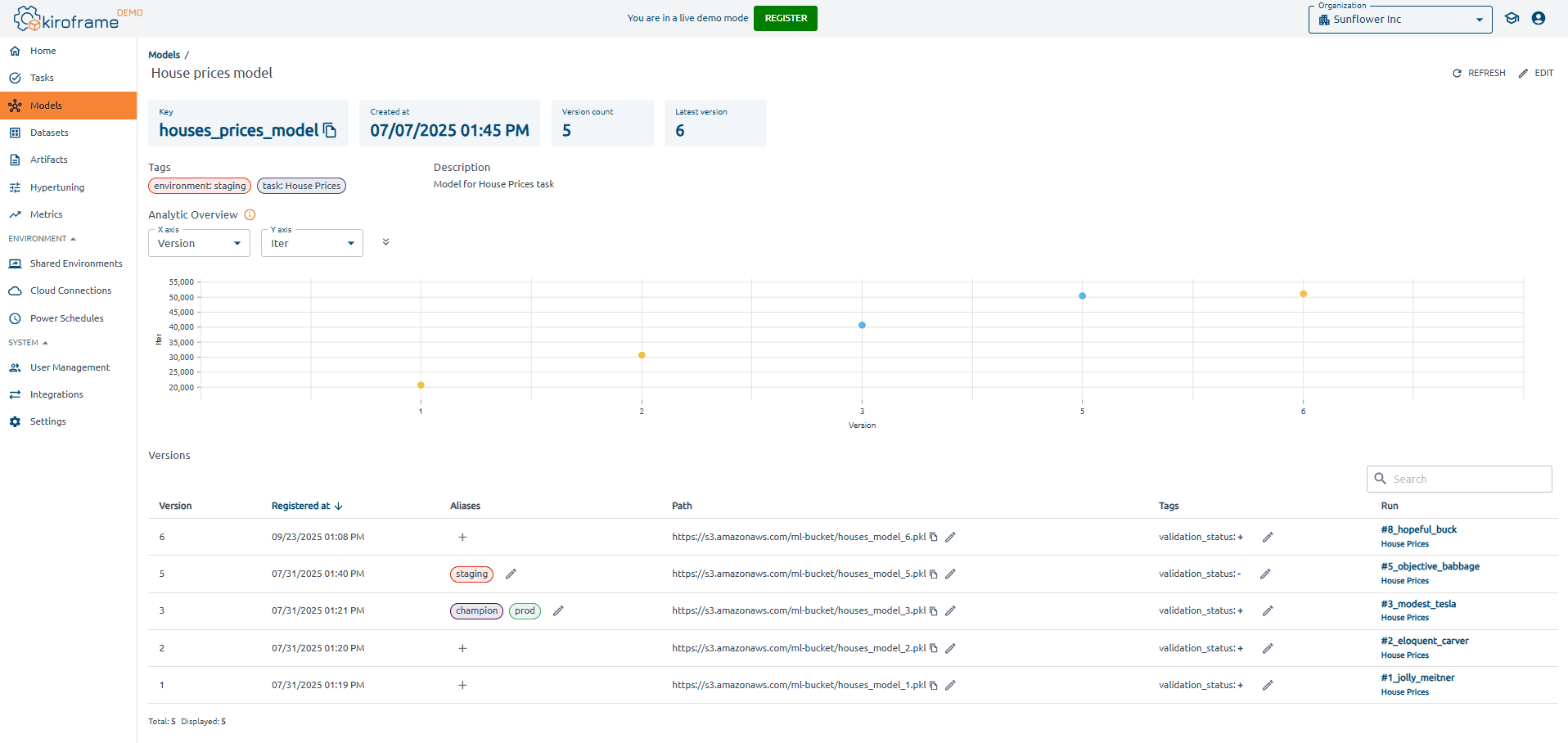
ML model versioning involves tracking all model artifacts — architectures, training pipelines, weights, hyperparameters, and results. Platforms such as MLflow and Kiroframe simplify this process by automatically recording experiment details and linking trained models with their corresponding datasets and configurations.
Kiroframe expands this principle further by offering version-controlled datasets and model profiles under one unified environment. This allows teams to compare different model iterations, roll back to previous versions, and maintain clear visibility across experiments — all in a centralized interface.
Code versioning
Managing source code is another essential part of MLOps versioning. Keeping consistent library dependencies and environment configurations across code versions prevents compatibility issues during training and deployment. Git remains the standard for code versioning, but MLOps-ready platforms integrate it into broader pipelines to synchronize code changes with model and data updates automatically.
Why versioning matters in MLOps
- Reproducibility: Ensures every experiment can be reliably recreated — crucial for debugging and validation.
- Accountability: Tracks who made what change, when, and why.
- Flexibility: Enables teams to revert, compare, or branch workflows effortlessly.
- Collaboration: Makes it easier for ML engineers, data scientists, and DevOps teams to work on shared projects without losing visibility.
By adopting strong versioning practices — and tools like Kiroframe, which unifies model, dataset, and experiment tracking — organizations can build ML workflows that are both transparent and dependable
2. Testing — ensuring model quality and pipeline reliability
Testing is a cornerstone of the MLOps lifecycle, ensuring that every component of a machine learning system — data, models, and code — functions reliably and consistently. It minimizes errors, detects issues early, and validates that ML models perform as intended under real-world conditions. Effective testing transforms machine learning from a research exercise into a repeatable, production-ready process.
In MLOps, testing typically spans three core domains:
Data testing
High-quality data is the foundation of any successful ML model. Data testing validates both the integrity and consistency of datasets used in training and inference. Key practices include:
- Dataset validation: Detecting missing values, incorrect labels, or inconsistencies using statistical checks and visualization.
- Pipeline validation: Running automated unit tests on data preprocessing and feature engineering functions to ensure they produce consistent outputs.
Regular data validation prevents cascading errors downstream — ensuring the model learns from trustworthy, representative data.
Model testing
ML model testing focuses on verifying that trained models perform well on new, unseen data and generalize effectively. It also ensures alignment with business objectives and compliance requirements.
This includes:
- Evaluating model behavior: Checking how the model reacts to edge cases or unexpected input.
- Validating metrics: Comparing results such as accuracy, precision, recall, and fairness metrics against defined benchmarks.
- Testing non-functional aspects: Ensuring the model meets security, interpretability, and ethical standards.
Modern MLOps platforms like Kiroframe simplify this stage by linking testing outcomes with experiment tracking and model profiles.
In Kiroframe, teams can directly compare performance metrics, visualize accuracy curves, and detect regressions across model versions, accelerating the validation and improvement cycle.
Code testing
Code testing guarantees that the ML project’s logic, dependencies, and integrations remain stable as it evolves. It ensures that code changes do not introduce new bugs or break existing functionality.
It typically includes:
- Unit testing: Verifying individual modules and functions, such as data parsers or model wrappers.
- Integration testing: Validating that combined components — data pipelines, training scripts, and deployment logic — work together correctly.
- System and acceptance testing: Simulating end-to-end workflows with real or synthetic data to confirm readiness for production.
Why testing is vital in MLOps
Testing underpins every other principle of MLOps by:
- Improving monitoring: Detecting anomalies before they affect production.
- Supporting reproducibility: Confirming consistent results across multiple runs and environments.
- Enhancing automation: Integrating testing into CI/CD pipelines ensures smooth model deployment.
- Strengthening collaboration: Providing shared visibility into model behavior and performance metrics.
Robust testing practices — especially when integrated within unified MLOps environments like Kiroframe — enable teams to maintain model quality, streamline deployment, and build confidence in AI-driven decisions.
3. Automation — streamlining Machine Learning workflows
Automation lies at the heart of MLOps, transforming manual, repetitive processes into streamlined, efficient, and reliable pipelines. The level of automation within an organization directly reflects its MLOps maturity — the higher the automation, the faster and more consistent the entire ML lifecycle becomes.
Automating MLOps workflows reduces human error, accelerates development, and frees data scientists and engineers to focus on high-value tasks such as experimentation, model improvement, and innovation.
Data engineering automation
Data engineering is one of the most labor-intensive parts of the ML lifecycle. Automating this stage increases data quality and reduces time-to-insight.
Common automation practices include:
- Data ingestion and transformation: Automatically cleaning, validating, and enriching datasets ensures a consistent flow of reliable input data for model training.
- Feature engineering: Automating feature generation and selection helps create scalable data pipelines that can adapt to new inputs and formats with minimal manual tuning.
- Continuous data validation: Setting up recurring validation checks ensures that incoming data adheres to expected schema, distribution, and integrity standards.
These practices collectively reduce the risk of data drift and maintain data readiness for model retraining cycles.
Model automation
Model automation focuses on streamlining the processes of model creation, validation, deployment, and maintenance. Key automation elements include:
- Automated model training: Scheduling recurring training jobs as new data becomes available.
- Hyperparameter tuning: Using optimization algorithms or search strategies to select the best-performing model configurations automatically.
- Automated validation and deployment: Integrating validation tests and CI/CD pipelines ensures models move to production seamlessly and safely.
Code automation
Automation doesn’t stop at models and data. In MLOps, code automation ensures consistency and quality across the entire software ecosystem.
- CI/CD pipelines: Automatically build, test, and deploy new code and model versions using integrated pipelines.
- Code quality checks: Use static analysis, linting, and automated testing tools to maintain high code standards.
- Container orchestration: Automate environment setup and dependency management through containerization tools like Docker and Kubernetes.
This approach helps eliminate human errors, maintain code reproducibility, and ensure that every change — whether in data, model, or infrastructure — is validated adequately before deployment.
Why automation matters in MLOps
Automation strengthens nearly every other MLOps principle by:
- Enhancing version control: Automatically tracking and linking code, model, and data updates.
- Improving testing: Enabling automatic validation after each pipeline iteration.
- Simplifying monitoring: Triggering automated alerts and metric collection for model health.
- Supporting reproducibility: Ensuring that every run can be replicated under identical conditions.
By embedding automation into the ML lifecycle — and using integrated platforms like Kiroframe to orchestrate these workflows — organizations can significantly accelerate model delivery, reduce operational friction, and maintain consistent quality at scale.
4. Monitoring and tracking
After a model is trained and validated, it’s essential to monitor and track the processes leading up to deployment continuously — ensuring the accuracy, stability, and transparency of machine learning workflows.
In MLOps, monitoring doesn’t always mean production-level supervision. It also refers to observing and analyzing model performance during training and experimentation, where most optimization and improvement occur.
Monitoring and tracking provide visibility into every component of the ML pipeline — from datasets and features to training metrics and code executions — enabling teams to identify issues early and make informed, data-driven improvements.
Data tracking and validation
Reliable models begin with reliable data. Data tracking helps teams ensure that the datasets used for model training are consistent, versioned, and traceable throughout their lifecycle.
Core practices include:
- Versioning datasets: Keeping historical versions of datasets and metadata to enable easy rollback or comparison.
- Detecting anomalies in data: Identifying missing values, outliers, or inconsistent distributions that may affect training quality.
- Tracking data lineage: Documenting how datasets evolve through preprocessing, transformation, and feature engineering.
In Kiroframe, dataset tracking is built into the workflow, allowing teams to connect data versions directly to model runs, view change histories, and link performance differences to dataset updates. This transparency helps ensure reproducibility and accountability in ML experiments.
Model training performance tracking
Monitoring model behavior during training is just as crucial as post-deployment evaluation. This involves capturing both internal and external performance metrics, such as loss, accuracy, and computational efficiency, across training epochs.
Key focuses include:
- Profiling resource usage: Observing GPU, CPU, and memory utilization during training.
- Recording experiment metrics: Comparing multiple training runs side by side to identify the best-performing configurations.
- Evaluating hyperparameters: Tracking the effect of learning rates, batch sizes, and other hyperparameters on training outcomes.
Kiroframe excels at model profiling, helping teams analyze performance bottlenecks, tune hyperparameters efficiently, and optimize training workflows. By combining experiment tracking with visualization tools, it offers clear insights into model behavior before production.
Code and workflow tracking
In MLOps, reproducibility depends on knowing exactly which code version, dependencies, and parameters were used to generate each result. Code tracking includes:
- Version control integration: Logging every change in scripts, configuration files, and notebooks.
- Dependency tracking: Ensuring consistent environments between experiment reruns.
- Workflow traceability: Capturing execution histories to make results explainable and repeatable.
Why tracking and monitoring matter in MLOps
Comprehensive tracking enables ML teams to:
- Understand performance evolution: Analyze how model metrics improve or degrade with different datasets and hyperparameters.
- Ensure reproducibility: Recreate past results with identical configurations and inputs.
- Accelerate optimization: Pinpoint training inefficiencies and adjust models faster.
- Enhance collaboration: Share insights, results, and visualized metrics across teams seamlessly.
Through integrated model profiling, dataset tracking, and experiment visibility, platforms like Kiroframe empower ML and data engineering teams to maintain complete transparency over their development process — building stronger, more reliable machine learning workflows long before models reach production.
5. Reproducibility — building reliable and transparent ML workflows
Reproducibility ensures that experiments and models yield the same results when repeated under identical conditions — regardless of who runs them or where they’re executed. In essence, reproducibility builds trust in machine learning systems by making outcomes explainable, verifiable, and transparent.
Without reproducibility, even the best-performing model becomes a black box — difficult to validate, compare, or improve over time. Achieving it requires a disciplined approach across data, models, and code, combined with structured experiment tracking and documentation.
Data reproducibility
Every ML experiment begins with data, and the ability to reproduce results depends heavily on ensuring data consistency over time.
Key practices include:
- Dataset versioning: Keeping historical snapshots of training and validation datasets.
- Metadata tracking: Recording information about data sources, preprocessing steps, and transformations applied.
- Feature versioning: Storing versions of engineered features to maintain alignment between training and retraining.
- Documentation: Maintaining explicit data schemas, lineage records, and quality metrics for auditability.
Model reproducibility
Model reproducibility focuses on being able to recreate the same model performance — with the same configurations and hyperparameters — across environments.
Best practices include:
- Parameter consistency: Keeping hyperparameters, training settings, and random seeds identical across runs.
- Experiment tracking: Recording all configurations, model artifacts, and performance metrics.
- Environment synchronization: Ensuring consistent hardware, software, and library versions during training and evaluation.
With Kiroframe, teams can easily compare model versions, visualize performance differences, and identify what changes led to accuracy improvements or regressions.
Code reproducibility
Reliable machine learning workflows also depend on stable and consistent code environments. Code reproducibility ensures that all model training and evaluation scripts produce the same output every time they are executed.
This includes:
- Dependency version control: Managing framework and library versions (e.g., TensorFlow, PyTorch, NumPy) to avoid compatibility issues.
- Containerization: Using Docker or similar technologies to standardize execution environments.
- Environment configuration management: Capturing setup files (like requirements.txt or conda.yaml) to rebuild identical runtime contexts.
How reproducibility connects all MLOps principles
Reproducibility is not an isolated step — it’s the result of effective MLOps implementation.
It relies on:
- Versioning: Tracking data, model, and code changes.
- Testing: Validating model behavior across multiple runs.
- Automation: Ensuring consistency through CI/CD pipelines and workflow automation.
- Tracking and profiling: Capturing every experiment detail for later review or re-execution.
By adopting reproducibility-first practices — and leveraging platforms like Kiroframe for integrated dataset tracking, model comparison, and experiment visibility — ML teams can confidently rebuild past results, accelerate debugging, and establish a transparent foundation for long-term AI development.
Core MLOps principles and their best practices
MLOps Principle | Purpose | Key Best Practices | How Kiroframe Supports It |
1. Versioning | Tracks changes in data, models, and code to maintain consistency and traceability across the ML lifecycle. | Use Git/DVC for dataset and code versioning, document model versions, and link experiments to data changes. | Dataset and model versioning with traceable experiment histories. |
2. Testing | Ensures data, models, and pipelines function correctly before deployment. | Validate datasets and features, perform unit/integration testing, and monitor accuracy and fairness metrics. | Visual experiment tracking, model profiling, and performance comparison for early issue detection. |
3. Automation | Streamlines ML pipelines to minimize manual work and reduce errors. | Implement CI/CD for ML workflows, automate data transformations, model training, and validation. | Workflow automation for dataset management, hyperparameter tuning, and reproducible runs. |
4. Monitoring & Tracking | Provides visibility into model behavior, dataset evolution, and training performance. | Track metrics during model training, monitor dataset drift, and log experiment outputs. | Integrated model profiling and dataset tracking with detailed metric visualization. |
5. Reproducibility | Guarantees consistent results across experiments, environments, and time. | Version data and models, fix random seeds, record dependencies (requirements.txt, conda.yaml), and use containers. | Unified tracking of datasets, hyperparameters, and code for reproducible ML workflows. |
ML/AI Leaderboards provide a competitive framework for researchers and practitioners to assess and compare the performance of their models on standardized datasets. Learn how →